Apache Iceberg — Solution Considerations
Apache Iceberg is been buzzing for a while this post is to deep dive on what that means and its solution considerations
What is it?
Its a table format to store and interact with the Data
From user perspective who are familiar in SQLs it is a way to answer the question of what data is in this table? , its not the data that’s going to be in some database, but stored in a file that reside in a data lake (like s3) and then users can interact with that table with SQL. Some Data Warehouses support even loading this file as External files and enable Analytical query.
Multiple users and tools can read, write or interact with the table at same time. All the corresponding data is written as table. You can modify the underlying schema on existing file without other rows and columns are impacted

Solution Considerations:
Are you going to load and store all data in a data lake and access? (Data Lake)
- Ideal usecase , esp If you want to store and query directly from data lake or adopting a lakehouse architecture
Are you going to load and store all your data into a data warehouse?(Pure Data warehouse) such as AWS Redshift, Snowflake, Big Query, Synapse Analytics
- Not Applicable , you don’t need this as cloud warehouse take care of this for you
Are you going to load and maintain some data in data lake and some data in warehouse? (Delta Lake scenario)
Partial
- AWS : Apache Iceberg supports popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive and Presto. AWS services such as Amazon Athena, Amazon EMR, and AWS Glue, include native support Apache Iceberg for transactional data lake, often based on storage in S3.
- Snowflake - can query the data directly in Iceberg and treat as external table
- Google Big Query - Can support load and query from iceberg table. https://cloud.google.com/bigquery/docs/query-iceberg-data
Do you want to maintain data in Open Table format
- yes , but even parquet can also support this
If you want to deep dive more , here are some additional information
How it has emerged?
Netflix created it to solve the issues they faced on the big data format on performance, atomicity and reliability.
Some history: True heavy weight in the big data arena was Apache Parquet , which has been the go-to choice for the columnar storage file format .
Apache Iceberg has been designed to address some of the issues that is faced with Parquet file format.
Different characteristics
Below provides a high level comparison with Apache Parquet
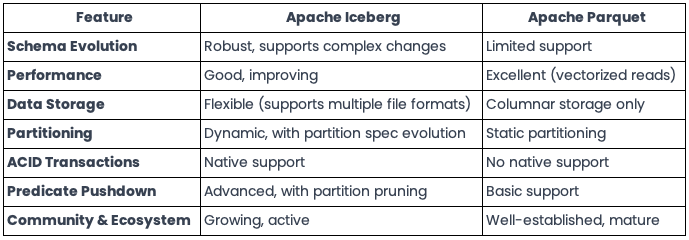
Schema Evolution-
Imagine you want to modify the schema while maintaining compatibility with older data — can we not able to do that in Parquet?. Parquet supports schema evolution to a certain extent, but it’s not as robust as Iceberg. For instance, Parquet allows you to add new columns or remove existing ones, but it doesn’t support evolving nested structures or updating partitioning specifications.
More details on these can be found on the Iceberg docs site.
Atomic Transactions-
Data remain consistent even during concurrent writes and reads , which is achieved by snapshot isolation and optimistic concurrency control .
Performance and Efficiency
Predicate Pushdown is supported which means -> filtering data at the storage level than at processing level. Even though Iceberg and Parquet support thism ,Because data is tracked at the file level in Iceberg format, smaller updates can be made much more efficiently.
In Ryan Blue’s presentation , he shares the results of an example use case at Netflix:
- For a query on a Hive table, it took 9.6 minutes just to plan the query
- For the same query on an Iceberg table, it only took 42 seconds to plan and execute the query
Storage
Parquet is a Columnar format BUT as mentioned earlier Iceberg on the other hand is table format than file format. It can work with various file formats including Parquet, ORC, Avro — so more flexibility
Iceberg takes partitioning to next level with dynamic partitioning and partioning spec evolution. This feature allows you to change partition schemas without rewriting the entire table
Event listeners
Event listeners in Apache Iceberg are a way to be notified of changes to an Iceberg table. They are implemented as a simple interface, Listener<E>, where E is the type of event that the listener is interested in.
Event listeners can be used to implement a variety of functionality, such as:
- Monitoring changes to an Iceberg table
- Updating downstream systems when an Iceberg table changes
- Ensuring that data is consistent across multiple systems
Logical view
- Iceberg provides the ability to continually expose a logical view to your users, decoupling the logical interaction point from the physical layout of the data.
- It is much easier to experiment with different table layouts behind the scenes. Once committed, the changes will take effect without users having to change their application code or queries. If an experiment turns out to make things worse, the transaction can be rolled back and users are returned to the previous experience.
File Structure
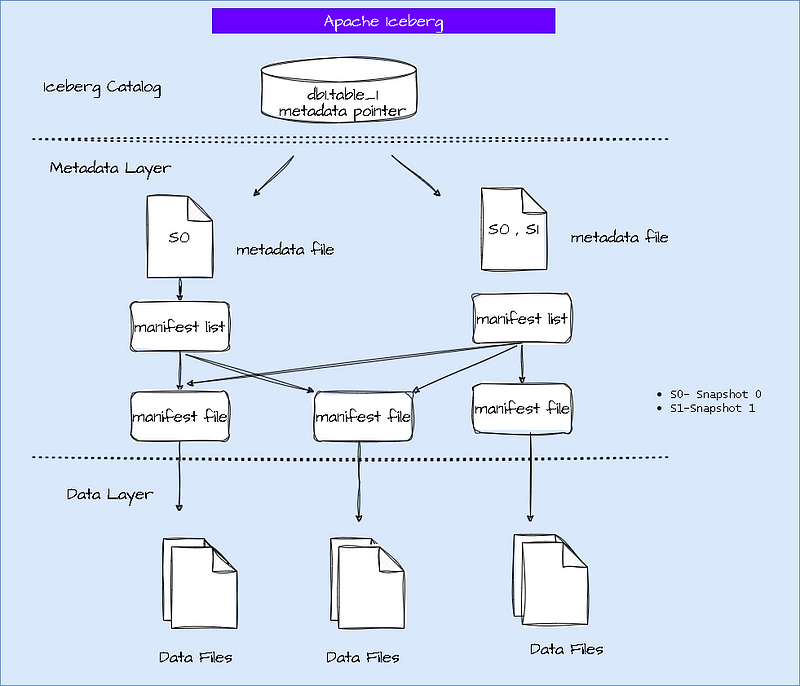
Link: https://www.youtube.com/watch?v=iGvj1gjbwl0
Courtesy:https://github.com/johnny-chivers/iceberg-athena-aws#main-tutorial
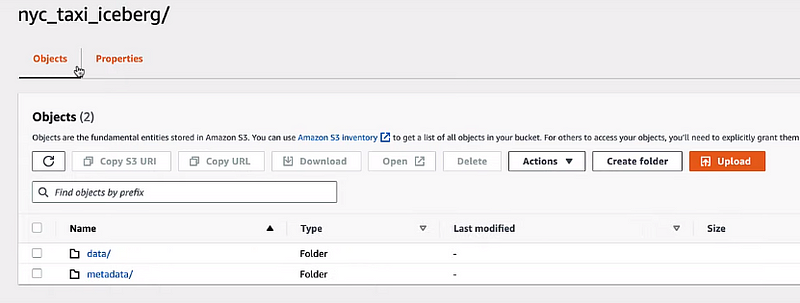
How it actually looks
use S3 example:
their will be two objects— data and metadata
Step by Step:
What happens after a create table( Iceberg is SQL like)
It creates a entry into a catalog which denotes a table is created. (still no data file )
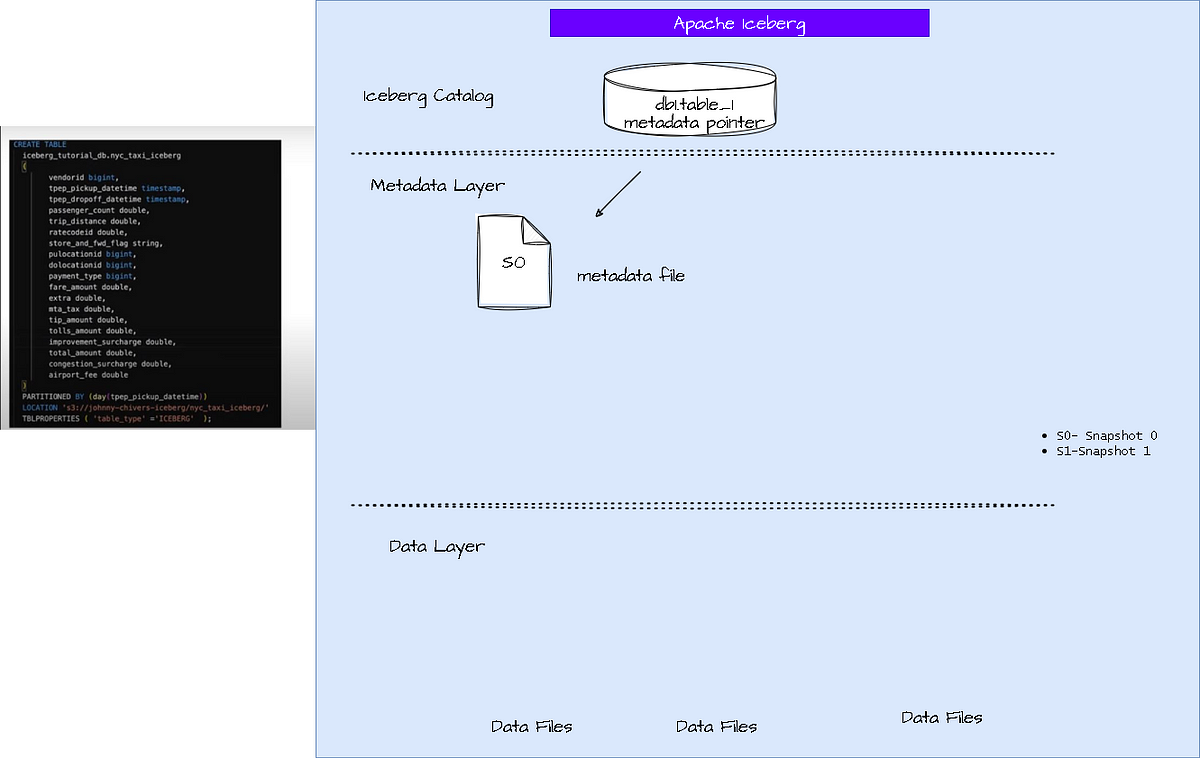
Now insert a record to the table
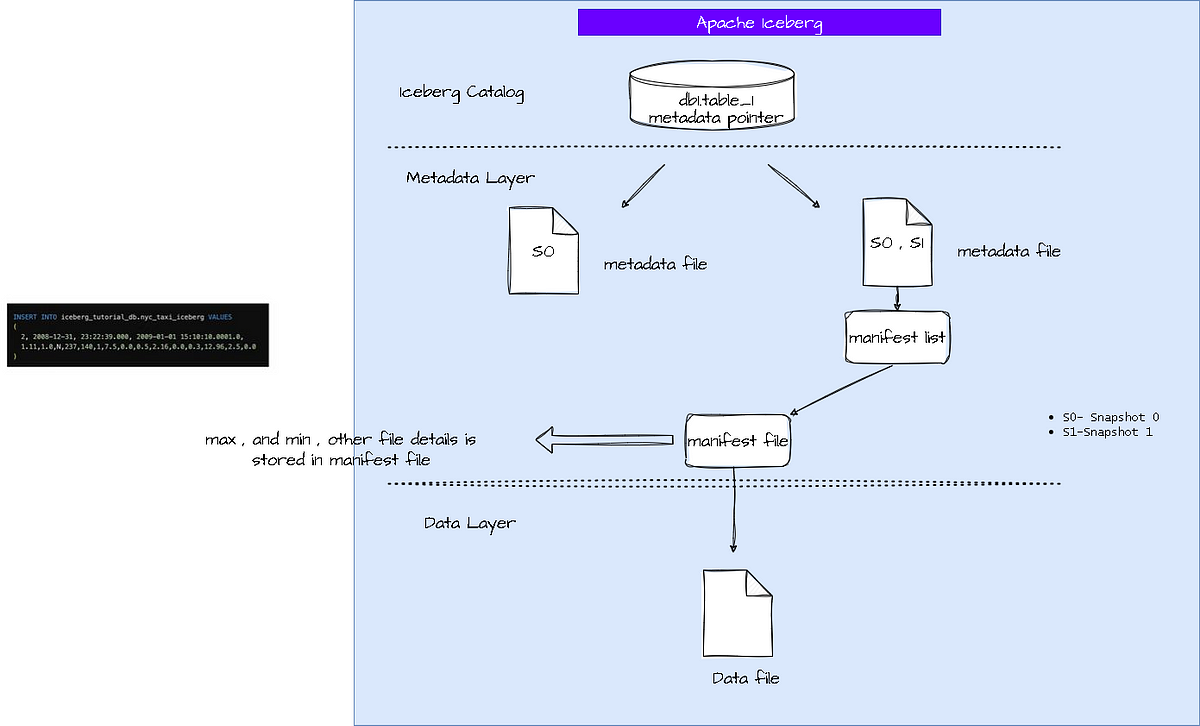
now if u update the record
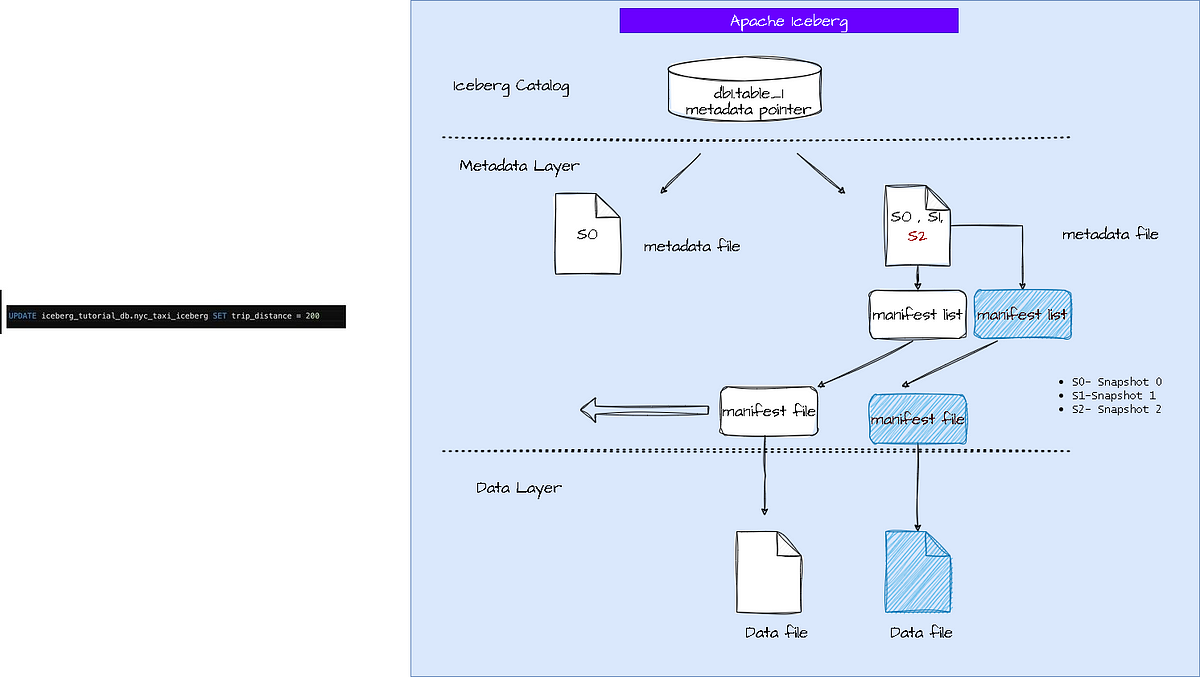
How it will actually look like
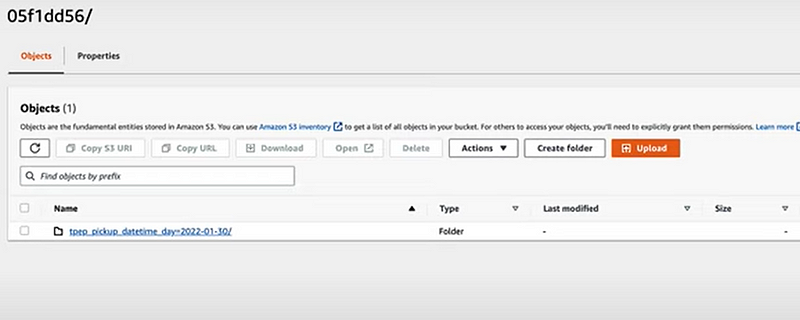
You need a catalogue and query engine to connect to navigate the data. In this case its AWS Glue and AWS Athena
Additional Cost consideration:
- Storage Efficiency: Iceberg has certain optimizations, like column pruning and partition pruning, that can reduce the amount of data read, potentially saving costs on storage. However, schema evolution might lead to duplicate data in the short term until older versions of data are garbage collected.
- Compute Costs: Efficient data retrieval can save on compute costs, as tasks complete faster. This means less CPU and memory usage in cloud environments or distributed systems.
- Integration Costs: While Iceberg integrates with popular computation frameworks like Spark, Flink, and Presto, there might be initial costs related to setting it up, especially if migrating from another table format or storage solution.
- Migration Costs: If you’re transitioning from another storage layer to Iceberg, there might be costs associated with the migration process, which includes time, resources, and potential cloud or infrastructure charges.
- Maintenance Costs: Like any technology, there are costs associated with maintaining and managing the infrastructure. This includes managing snapshots, performing garbage collection, and ensuring schema compatibility. There may also be costs related to training your team on the new system.
- Versioning Costs: One of Iceberg’s features is its ability to handle versioning and snapshots. While this is a beneficial feature, maintaining multiple versions of data can increase storage costs until older snapshots are deleted.
- Performance Tuning: Optimizing Iceberg for your specific workload can involve time and expertise, leading to associated costs. For instance, choosing the right partitioning strategy is essential for performance but might require experimentation.
- Vendor Lock-in: If you’re using a particular cloud provider’s storage solution and are considering moving to a more open format like Iceberg to avoid vendor lock-in, consider potential costs of transferring data out of your current cloud storage, as well as potential benefits in flexibility and potential cost savings in the future.
- Backup and Disaster Recovery: Backup strategies might differ with Iceberg, potentially affecting costs, depending on your chosen storage backend and associated charges for data retrieval or redundancy.
- Open Source: While Apache Iceberg is open source and free to use, implementing, customizing, and maintaining the software might require expertise. This could involve hiring or training staff familiar with the system.
In summary, while Apache Iceberg offers many benefits in terms of performance, flexibility, and scalability, there are costs to consider when implementing and maintaining it. It’s essential to weigh these costs against the potential benefits for your specific use case and infrastructure.